Neural Keyphrase Generation via Reinforcement Learning with Adaptive Rewards. Hou Pong Chan, Wang Chen, Lu Wang, Irwin King. ACL 2019. [PDF]
动机
本篇论文主要解决目前keyphrase generation任务中存在的两个不足:
(1)模型生成的keyphrase比真实的keyphrase个数少
(2)已有评价标准依赖词的完成匹配(不完全匹配就算错,如真实keyphrase为SVM,模型生成的keyphrase为support vector machine也算错)
方法
keyphrase根据是否在原文中是否出现分present和absent,这里将一个document的所有keyphrase拼接成一个序列,present在前absent在后,并通过利用seq2seq编码document来生成所有的keyphrase。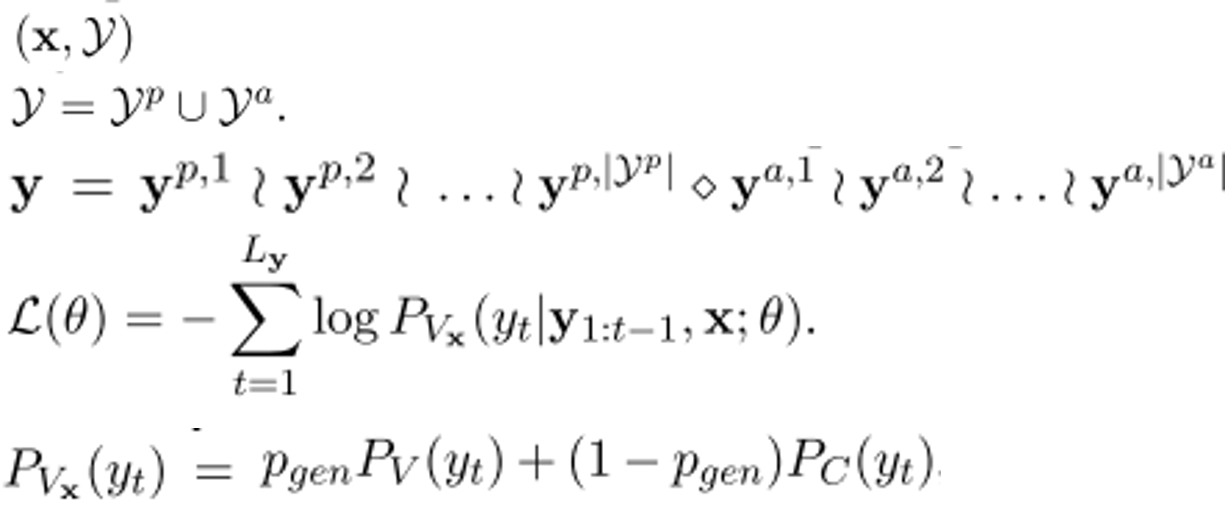
针对第一个不足,作者使用了reinforcement learning,
sample policy: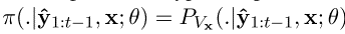
reward function: RF1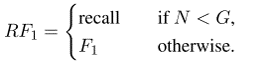
N为目前已生成的keyphrase个数,G为真实keyphrase个数。作者认为当生成keyphrase的个数还少于真实keyphrase个数时,应该鼓励模型去生成更多的keyphrase,所以用recall作为reward;当个数足够时,除了要求个数也要要求正确性,所以用的F1。看到这里可能也有人会有疑问,为什么前面只重视个数而忽视正确性呢?为什么不改变个数和正确性的权重呢(可以认为是F1的变形)?在这里我个人认为作者可能是实验驱动,只用recall就有效果了;如果没有效果作者可能会去设计吧。。。
presen keyphrase 和 absent keyphrase分别计算reward:
针对第二个不足,思路也很容易理解,就是找keyphrase的各种形式,作者这里主要有三个方法
(1)Acronyms in the ground-truths
(2)Wikipedia entity titles
(3)Wikipedia disambiguation pages
然后作者在四个baseline基础上分别验证了方法的有效性,并且对生成的keyphrase的个数、RF1进行了分析。